Word2Vec로 word embedding 이해하기
Word2Vec을 알면 좋은 이유
Word2Vec(2013)은 소개된지 10년이 다되가는 모델이다. 성능면에서 보면 더이상 활용할 필요가 없는 구식 모델이다. 그럼에도 많은 사람들이 Word embedding에 대한 개념을 이해하기 위해 Wor2vec을 공부하고 있다.
Word2Vec의 단순한 구조는 단어가 어떻게 vector space에 표현될 수 있는지를 직관적으로 이해하는데 도움을 준다. 또한 이러한 이해는 Word embedding에 기반한 최신 모델을 이해하는데 도움이 된다. 현재 널리쓰고 있는 Transformer 기반의 Bert, Electra, GPT 같은 모델은 결국 단어를 vector 공간에 효과적으로 배치하는 방법에 대한 기술 축적의 결과물이기 때문이다. 고도화 된 기술을 걷어내면 본질에는 Word2Vec이 있다.
이 글에서는 Word2Vec 도식화 구조를 기반으로 설명을 진행한다. 모델을 처음 배우는 단계에서 논문에서 소개한 도식화 구조를 이해하는게 중요하다 생각하는데, Word2Vec 도식화는 처음 보기에 직관적으로 와닿는 편이 아니다. 검색 능력의 한계인지 몰라도 혼선을 빚은 부분에 대한 설명을 찾지 못해 애매한 체로 넘어갔었는데, Word2Vec를 복습할 겸 도식화 그림을 중심으로 모델의 구조를 정리했다.
Word2Vec 알고리즘에는 Continuous Bag of words(CBOW) 방법과 Skip-Gram 방법이 있다. 그 중 성능면에서 Skip-Gram이 우수하기 때문에 여러 글에서 Skip-Gram을 위주로 설명한다. 다른 글도 참고하여 Word2Vec를 이해하는 것을 권하기 때문에 이 글에서도 더 쉽게 찾아볼 수 있는 Skip-Gram에 대한 도식화를 중심으로 설명한다.
input data 전처리
모델을 이해하는데 있어 중요한 내용중 하나는 모델이 어떤 input data를 받는지를 아는 것이다. 모델이 어떤 데이터 구조를 필요로 하는지 알아야 input data가 어떻게 모델 내에서 가공 되는지 이해할 수 있다.
W2V은 단어와 단어 관계를 학습하는 모델이다. 핵심 단어를 Input 데이터로 하여 주변 단어를 output으로 찾는 과정을 학습한다.
W2V은 One-hot encoding 된 단어를 Input data로 받는다. One-hot encoding이라 하면 현재 단어를 1로 표시하고 나머지 단어를 0으로 한 vector를 의미한다. 문장 하나를 예시로 들면, ‘나는 어제 맥북을 구매했다’라는 문장은 [나,-는,어제,맥북,-을,구매,-했다]로 단어를 나눌 수 있고 '나'라는 단어는 [1,0,0,0,0,0,0]로, '맥북'이라는 단어는 [0,0,0,1,0,0,0]으로 표현된다.
문장이 많아지고 그에 따라 단어 수도 증가하면 그에 따라 단어를 표현하는 리스트(차원)의 크기도 증가한다. 학습 데이터로 활용할 수천개 문장에 대한 단어를 one-hot encoding으로 표현한다고 생각해보자. 수천 개의 문장 내 쓰인 단어를 종합해보니 총 10,000개 단어가 된다고 고려할 때, 단어 하나를 표현할 때 9999개의 0과 1개의 1로 표현 해야한다.
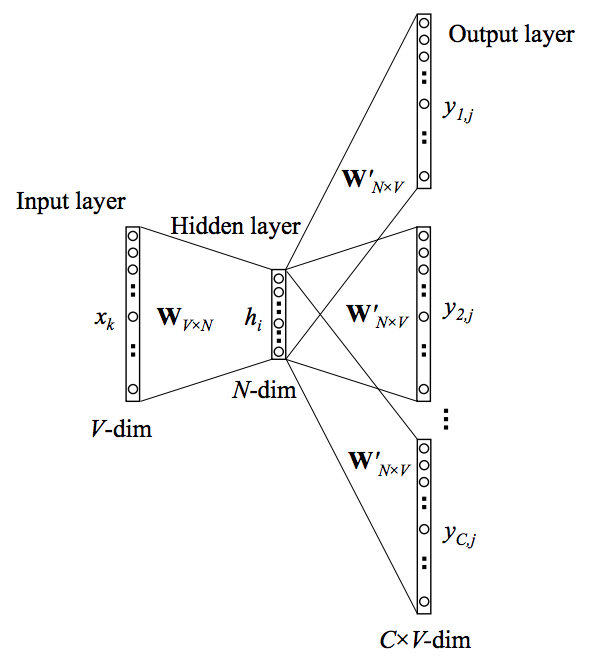
도식화 첫번째 부분의 네모난 막대기와 아래의 V-dim은 one-hot encoding을 의미한다. V는 학습 데이터의 총 단어 개수를 의미하며 네모 막대기는 [1,0,....0,0]과 같은 one-hot encoding 된 단어를 의미한다.
V가 단어 개수이고, 네모 막대기가 one-hot encoding화 된 단어라는 것을 알고 있으니 지금부터는 input data를 V차원의 one-hot vector라 부르겠다.
Input layer에서 hidden layer까지 데이터 흐름
이번 단락에서는 전처리된 데이터를 활용해 hidden layer를 구하는 흐름을 설명한다.
Word2Vec의 Skip-Gram 구조는 input layer - hidden layer - output layer로 총 3개의 layer로 구성된다. 3개의 layer를 사용하므로 2개 Weight 행렬(W와 W’)이 사용된다. 차차 알아가겠지만 2개의 weight 행렬 중 첫번째 weight 행렬(W)이 모델이 학습시키는 대상이자 Word2Vec 모델의 알맹이이다.
 V = 단어 개수, N = feature 개수(기본 값 300), C = 참고할 단어 개수(Window)
V = 단어 개수, N = feature 개수(기본 값 300), C = 참고할 단어 개수(Window)
‘input 데이터 전처리’ 단락에서 input layer의 데이터 형태가 one-hot-vector라고 설명했다. 개별 단어들은 one-hot-vector로 encoding 되었으며 개별 one-hot-vector의 차원은 단어의 총개수인 V라고 했다. 10,000개의 단어 리스트인 경우 개별 단어는 10,000차원을 지닌다 했다.
첫번째 Weight 행렬은 VxN 구조의 행렬이다. V는 단어의 총 개수이고 N은 차원 개수이다. N은 임의의 값으로 설정해도 무방하며 논문에서는 300을 사용하므로 이 글에서도 N을 300으로 설명한다.
Word embedding(=Distributed Representation(분산 표상)) 목표
word embedding의 1차 목표로는 단어 표현에 필요한 차원을 줄이는것이다. one-hot encoding은 단어 개수에 비례해 차원 개수가 늘어나는 문제가 있다. 단어가 100개면 100차원, 1000개면 1000차원이 된다.하지만 차원이 커질수록 연산량이 급증하기 때문에 단어 개수를 늘리는데 한계가 있다.
word embedding의 2차 목표는 단어간 유사도를 표현하기 위함이다. one-hot encoding에서 개별 단어의 내적은 0이 되므로 서로 연관성을 나타낼 수 없다. Distributed Representation는 학습을 통해 단어 간 좌표평면 상 위치를 조정하는 과정이므로 학습이 완료된 경우 단어간 유사도를 계산할 수 있다.
아래 블로그 링크를 보면 관련 내용을 자세히 다루고 있으니 Distributed representation 부분을 읽어보자.
hidden layer를 만들기 위해서는 input layer와 첫번째 Weight 행렬을 곱셈해야한다. 따라서 hidden layer는 1xV * VxN = 1xN 행렬 구조가 된다. hidden layer는 특정 input 데이터의 vector 공간 내 위치이다. input layer는 단어의 one-hot vector이고, weight 행렬은 최종적으로 얻고자 하는 word embedding이라 설명했다. 이 둘을 곱하면 해당 단어의 word embedding vector 추출할 수 있다.
말로서는 이해가 어려우니 예시를 들어보자. [참새, 커피, 마시다, 잡다] 라는 단어 리스트가 있다. 참새는 one-hot vector로 [1,0,0,0], 커피는 [0,1,0,0], 잡다는 [0,0,1,0], 마시다는 [0,0,0,1]이 된다.
weight 행렬
Weight 행렬은 위와 같이 4개의 단어에 대한 3차원의 행렬이다. 내부 값은 개별 단어의 vector 공간 내 위치이다. 참새의 vector 공간은 [1.2, 2.1, 3.6], 커피는 [3.5, 2.8, 4], 잡다는 [1.2, 0.8, 3.0], 마시다는 [4.1, 1.7, 2.8]이ㅣ 된다.
이제 one-hot vector와 weight 행렬을 활용해 hidden layer를 구해보자. input 값이 커피인 경우 hidden layer 계산은 아래와 같다. 행렬 곱셈의 결과값은 weight 행렬에 두 번째 위치한 값과 같음을 알 수 있다. 즉 커피의 embedding vector이다. input layer와 weight 행렬을 곱해 hidden layer를 구하는 과정은 커피의 embedding vector를 불러오는 과정으로 이해할 수 있다. 즉 hidden layer는 특정 단어의 embedding vector가 된다.
hidden layer에서 output layer까지
다음으로 output layer를 구하는 단계이다. output layer은 hidden layer와 두번째 Weight 행렬을 곱해서 구한다. 도식화된 output layer를 이해하기 위해서는 skip-gram에 대해 알아야 하므로 skip gram을 설명한 뒤output layer에 대해 설명하겠다.
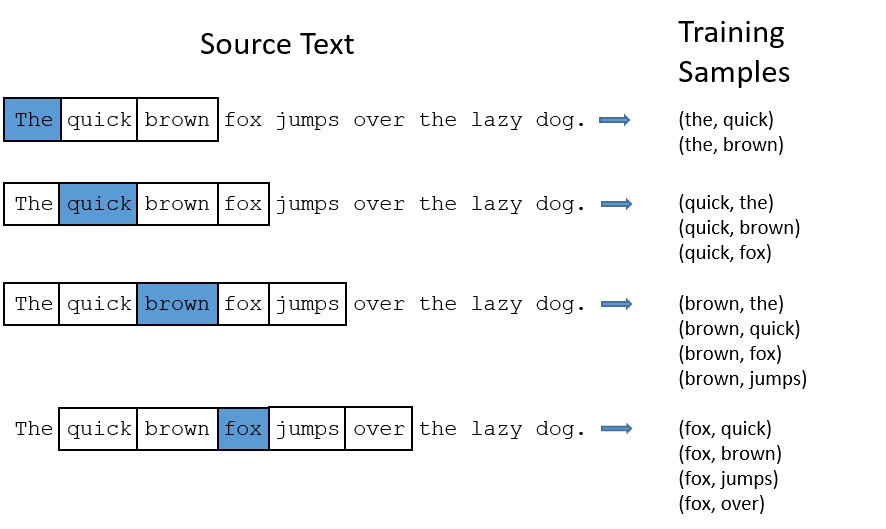
Skip-Gram은 학습을 위해 중심단어와 주변단어를 샘플링한다. 파란색 배경이 있는 단어가 중심단어이고 배경이 없고 윤곽만 있는 단어가 주변 단어이다. 첫번째 학습을 보면 the와 주변 단어인 quick과 brown을 샘플링한다. 이때 (the,quick), (the,brown) 형태에서 보듯 개별적으로 학습한다.
학습 절차는 다음의 순으로 진행된다. 모델은 (the,quick)을 학습한다. 모델은 the 다음에 나올 단어들의 확률을계산하기 위해 모든 단어에 대해 the 다음에 나타날 확률을 계산한다. 10,000개의 단어 리스트가 있다면 10,000개 단어 모두에 대해 the 다음에 나타날 확률을 계산한다. the 다음에 quick이 나왔다는 것을 학습시키기 위해 the 다음에 quick이 나올 확률을 올리고 나머지 확률을 낮추는 방식으로 weight를 조정한다. 같은 방식으로 (the, brown), (quick, the), (quick,brown) 을 계산한다.
아래 그림은 중심단어를 기준으로 2개의 주변 단어를 학습(Window = 2)하는 과정을 나타낸다. 1회에 학습할 단어 개수를 window라는 용어로 부른다. window가 2이면 중심단어를 기준으로 좌우 2개 단어 도합 4개의 단어를 1회 학습으로 간주한다. brown을 학습하기 위해 (brown, the), (brown, quick), (brown, fox), (brown, jumps)를 샘플링하고 학습하면 1회 학습이 완료된다. 중심 단어 기준 주변 단어를 몇 개까지 포함할 것일지에 따라 모델이 학습하는 양이 달라짐을 알 수 있다.
CBOW보다 Skip-Gram을 선호하는 이유
Skip-Gram의 W 업데이트 횟수가 CBOW보다 많기 때문
주변단어로 중심단어를 예측하는 CBOW에 비해 Skip-gram의 성능이 좋은 이유가 바로 여기에 있습니다. 언뜻 생각하기에는 주변의 네 개 단어(window = 2인 경우)를 가지고 중심단어를 맞추는 것이 성능이 좋아보일 수 있습니다. 그러나 CBOW의 경우 중심단어(vector)는 단 한번의 업데이트 기회만 갖습니다.
반면 윈도우 크기가 2인 Skip-gram의 경우 중심단어는 업데이트 기회를 4번이나 확보할 수 있습니다. 말뭉치 크기가 동일하더라도 학습량이 네 배 차이난다는 이야기이죠. 이 때문에 요즘은 Word2Vec을 수행할 때 Skip-gram으로 대동단결하는 분위기입니다.
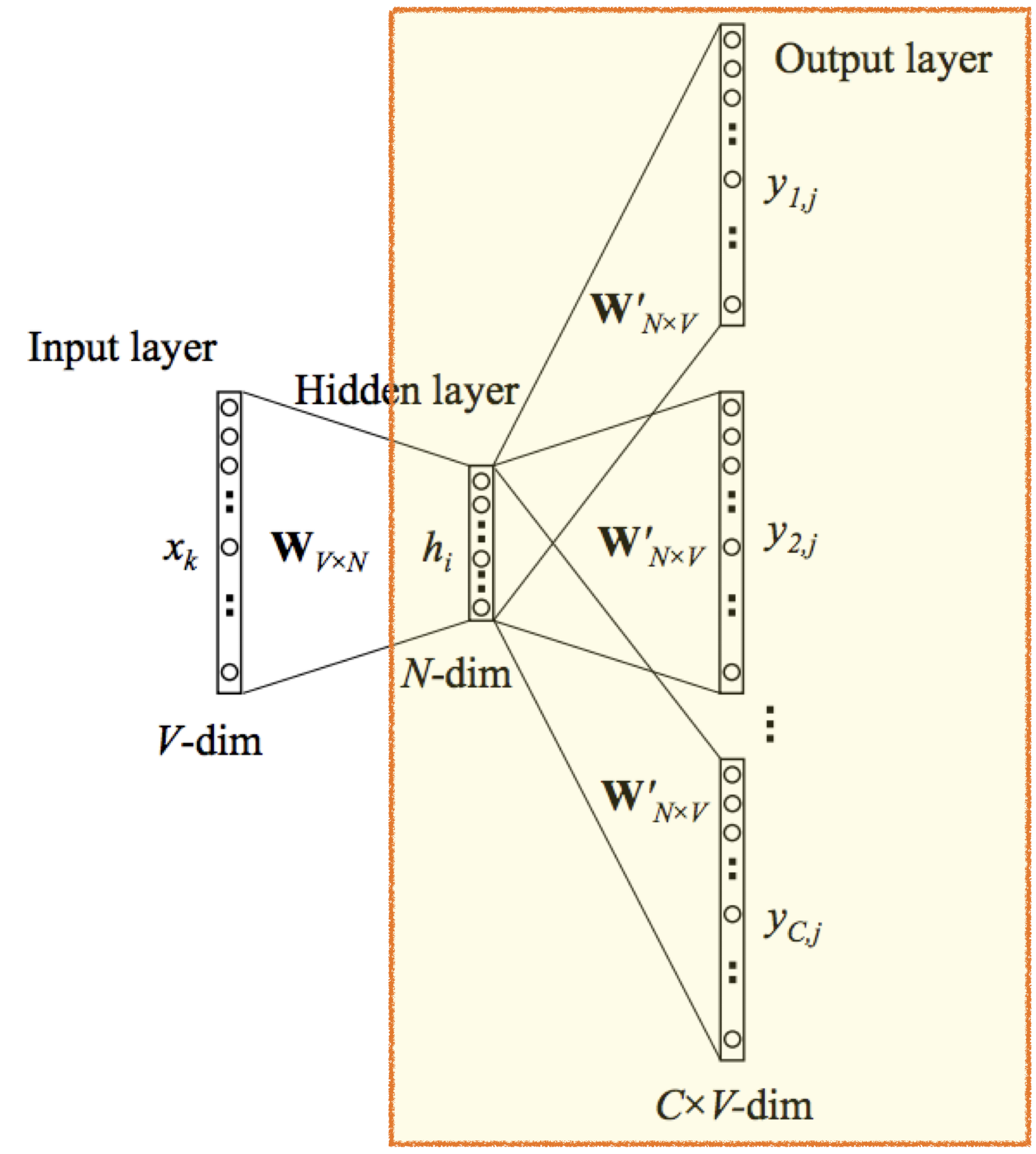 V = 단어 개수, N = feature 개수(기본 값 300), C = 참고할 단어 개수(Window)
V = 단어 개수, N = feature 개수(기본 값 300), C = 참고할 단어 개수(Window)
도식화 그림에서 output layer는 skip-gram의 1회 학습 구조를 나타낸다. output layer는 v-dim이 C개 있는 구조로 표현되는데, C는 중심단어가 주변단어를 학습하는 횟수와 같다. window가 2인 경우 중심단어 기준 좌우 주변단어 2개에 대해 총 4번 학습하게 된다. 그래서 window가 2인 경우 C는 4가 된다. 학습은 4번 진행되지만 중심단어를 학습하는 것이 목적이므로 1회의 학습으로 간주해야한다. 도식화 그림은 이를 반영한 것이라 할 수 있다.
brown을 학습한다면 (brown, the), (brown, quick), (brown, fox), (brown, jumps) 4번의 학습이 1회 학습이된다. 도식화 그림에서 개별 학습은 행렬로 표현된다. (brown, the)은 첫번째 학습이므로 , (brown,quick)은 두번째 학습 이므로 가 되는 방식이다.
여기서 주의해야할 점은 output layer의 도식화 그림은 skip-gram의 학습 방법을 표현한 것이지 output layer의 행렬이 CxV 행렬이라는 의미는 아니다. output layer의 그림은 C번의 학습 과정을 나타낼 뿐 개별적으로 진행되는 과정임을 명심해야한다. (brown, the)를 학습해 weight를 조정하고 그 다음 (brown, quick)를 학습해 weight를 조정하고 그 다음은(brown, fox), 그 다음은 (brown, jumps)를 학습해 weight를 조정하면 brown의 학습이 종료되고 다음 중심단어로 넘어가 학습을 시작한다.
이러한 구조이기 때문에 행렬을 이해한다면 output layer를 이해할 수 있게 된다. 행렬은 hidden layer와 두번째 weight 행렬을 곱해서 구한다.
두번째 weight 행렬도 첫번째 weight 행렬과 마찬가지로 개별 단어의 word embedding을 나타낸다. 기능은 동일하지만 첫번째 weight 행렬의 값과는 다르다. 첫번째 weight 행렬에서는 행 vector가 개별 단어의 embedding 값을 의미했다면 두번째 weight 행렬에서는 열 vector가 개별 단어의 embedding 값을 의미한다. 단순하게 생각해서 VxN 행렬을 NxV 행렬로 Transpose 했기 때문에 행과 열의 위치만 바뀐 것이다.
두번째 Weight 행렬의 구조를 보고 첫번째 Weight 행렬을 Transpose하면 두번째 Weight 행렬이 되는 것 아닌가 생각할 수 있다. 첫번째 weight 행렬을 Transpose 한다고 두 번째 weight 행렬이 되는건 아니라고한다. 학습이 잘됐을 땐 두 weight 행렬 중 아무 행렬이나 embedding 행렬로 사용 가능하지만 일반적으로 첫번째 W를 사용한다고 한다.
두번째 weight 행렬
=
hidden layer와 두번째 weight 행렬을 곱하면 output layer를 구할 수 있다. hidden layer는 특정 단어의 embedding이다. 커피의 hidden layer는 커피의 embedding vector인 [3.5, 2.8, 4]이다. 두번째 weight 행렬은 word embedding을 transpose한 구조이다. (기능은 같지만 안의 실수 값은 다르다고 한다.) 아래 식과 같이 커피와 리스트 전체([참새,커피,마시다,잡다])를 곱해 output layer를 구한다.
이렇게 계산한 output layer에 softmax를 적용하면 커피 다음에 오는 단어의 확률을 구할 수 있다.
=