Transformer Positional Encoding 이해하기
들어가며
이 글은 Transformer의 구조 중 Positional Encoding에 대한 설명과 이에 대한 참고자료를 정리하였습니다.
단어의 위치 정보 생성하기
Poisional Encoding은 문장 내 단어의 "위치 정보"를 벡터로 표현한 한 것입니다. 이러한 벡터 값이 왜 필요로 하는지, 어째서 Transformer 모델에 중요한지는 Transformer가 탄생한 배경을 이해한다면 충분히 유추할 수 있습니다.
기본적으로 Transfoermer의 기본 골격인 Encoder와 Decoder는 Transformer 모델에서 새롭게 소개된 구조가 아닙니다. 단지 Transformer는 RNN 기반의 seq2seq모델을 Attention을 활용해 구현한 모델일 뿐입니다.
물론 Attention만을 활용해 seq2seq 모델을 구현하는 것 자체가 기술적인 도전이었고, 많은 사람들에게 Attention의 장점인 병렬 연산과 문장 내 모든 단어 정보를 참조 할 수 있는 기능을 각인 시킨 모델이었기 때문에 Transformer 기반 모델이 사실상 NLP 모델의 표준으로 자리잡게 될 수 있었습니다.
Attention을 활용해 Transformer 모델을 구현함에 있어 해결해야할 기술적인 난제는 대표적으로 병렬연산을 수행함으로서 잃게되는 위치정보 값이 있습니다. 기존 RNN 기반의 seq2seq 모델은 문장을 학습할 때 단어(엄밀히 말하면 토큰)하나를 순차적으로 학습 했기에 자동으로 단어 간 간격의 범위에 따라 단어의 의미를 다르게 부여한다거나, 특정 단어가 오는 패턴등을 학습 할 수 있었습니다.
이해를 돕기 위해 예시를 하나 들어보겠습니다. "나는 오늘 학교에 안 갔다"라는 문장이 있습니다. 이 문장을 토크나이징 하게되면 [나, -는, 오늘, 학교, -에, 안, 갔다.]로 구분 됩니다. 여기서 "안"이라는 단어는 부정의 의미로 사용되고 있으며 "안" 다음에 위치하는 토큰인 "갔다"를 통해 부정의 의미를 파악할 수 있습니다. 이 문장과 비슷한 문장인 "나는 오늘 학교 안에 갔다"를 분석해보겠습니다. 여기서의 단어 "안"은 내부를 의미하며 "-에"라는 단어를 통해서 이를 파악할 수 있습니다.
이러한 예시처럼 특정 단어 다음이라는 위치정보 하나만으로도 이 단어가 어떠한 의미로 사용되는지, 어떠한 단어가 나올 가능성이 높은지를 판단할 수 있는 훌륭한 정보로서 활용 될 수 있다는 점을 볼때, 위치 정보를 포함할 수 없는 Attention은 상당한 페널티가 부여 받은 것이라 할 수 있습니다.
이러한 점에 기반한다면 Positional Encoding은 Seq2Seq 구조를 Attention으로 구현하기 위해 넘어야 하는 기술적 과제 중 하나인 문장 내 단어의 위치 정보를 반영할 수 없는 문제를 해결하기 위한 아이디어이자, Attention 만으로 seq2seq 모델을 구현할 수 있는 묘수라 할 수 있습니다.
중복되지 않은 벡터를 생성하려면
이제 Positional Encoding이 Transformer의 핵심인 이유를 이해했으니 Positional Encoding은 어떠한 방법으로 구현됐는지, 왜 이러한 방법을 왜 택했는지를 살펴보겠습니다.
본격적으로 설명하기에 앞서 내용 이해에 필요한 기본 지식인 삼각함수에 대한 유용한 참고자료를 소개하겠습니다. 원리 이해를 기반으로 쉽게 설명한 자료라 sine, cosine에 대한 부담을 가볍게 털어내실 수 있습니다.
❖ 단어 정보를 해치지 않는 선에서
Positional encoding은 병렬 연산으로 잃게되는 위치 정보를 반영하는 아이디어라고 설명했습니다. 논문에서는 이러한 위치 정보를 단어 임베딩에 직접 더하는 방법으로 반영하고 있습니다. 워드 임베딩을 통해 개별 토큰을 512차원으로 변환하고 개별 단어 임베딩에 똑같이 512차원의 위치 임베딩을 더해 학습에 활용되는 임베딩을 생성하는 방식입니다.
여기서 고려해야할 사항은 단어 임베딩과 위치 임베딩을 단순히 더하는 방식이므로 위치 임베딩의 값이 너무 커지게 된다면 단어 정보가 손실될 수 있다는 점입니다. 그렇기에 단어 임베딩 정보를 해치지 않는 선에서 임베딩의 크기를 선정해야합니다. 그 다음으로는 위치 정보를 표현하는 벡터들이 서로 중복되어서는 안됩니다. 문장 내 단어의 위치가 개별적인 값을 갖고 있어야 명확한 위치 정보가 반영된 것이라 할 수 있습니다.
논문의 저자는 이러한 조건을 만족시키는 위치 임베딩 생성하기 위해 sin과 cos 함수를 이용합니다. 아래 식은 논문에 소개된 positional encoding 공식이며 이제부터 이 공식을 이해해보도록 하겠습니다.
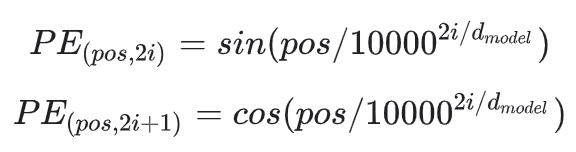
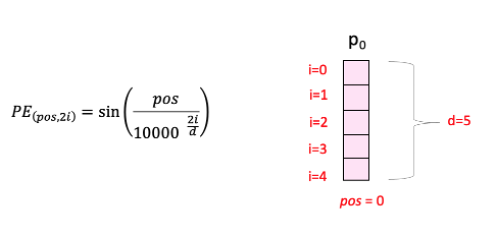
공식에 사용된 pos, i, d는 아래 그림을 통해 쉽게 이해하실 수 있습니다. 분홍색의 벡터는 pos번째 위치한 단어의 위치 벡터이며 백터의 내부 원소는 i로 표현됩니다. d의 경우는 단어 하나를 표현하는데 사용된 임베딩의 크기(논문에서는 512)입니다.
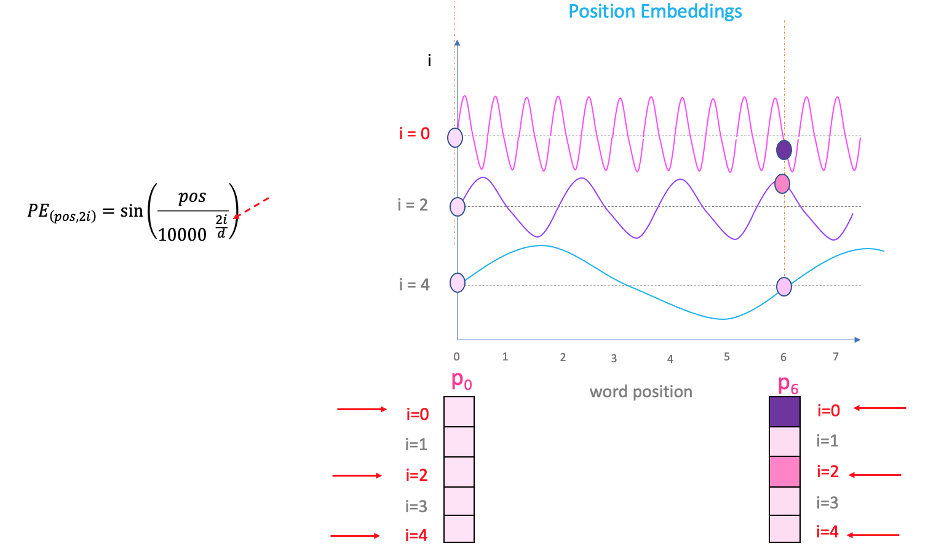
벡터 내부의 원소 위치에 따라 다양한 진폭의 sin, cos 그래프가 그려지며, 개별 원소는 원소 내 위치(i)와 문장 내 단어의 위치(pos)의 위치에 따라 값을 부여받게 됩니다. 아래의 그림을 보면 i의 크기에 따라 그래프의 진폭이 다름을 확인할 수 있고 이를 통해서 최대한 중복되지 않은 위치 임베딩을 생성할 수 있게 됩니다. 그리고 이러한 방식으로 512개 embedding의 원소들이 sin과 cos 값으로 번갈아가며 채워지게 됩니다.
❖ 코드로 이해하기
positional encoding은 문장 내 위치한 단어 순서에 대한 임베딩입니다. 1개 문장이 128개 토큰으로 구분될때 토큰을 임베딩하고나서 개별 단어의 위치에 부합한 유니크한 위치 정보를 추가하며, 어떠한 문장이라도 N번째 단어는 모두 동일한 임베딩을 더하게 됩니다.
따라서 위치 임베딩을 한 번 생성하게 되면 계속해서 동일한 임베딩을 활용해서 문장을 학습시켜야합니다.
아래 코드는 positional encoding을 직관적으로 표현한 구조입니다. 문장 내 단어의 위치(pos)에 따라 벡터 원소의 위치(i)가 개별적인 값을 부여받으며 위치 임베딩이 만들어집니다. 짝수일 경우에는 sin 값을, 홀수인 경우에는 cos 값을 부여받으며, 벡터 원소의 위치에 따라서도 그래프의 주기가 달라지므로 다른 값을 부여받게 됩니다.
import numpy as np
def getPositionEncoding(seq_len, d=512, n=10000):
P = np.zeros((seq_len, d))
for k in range(seq_len):
for i in np.arange(int(d/2)):
denominator = np.power(n, 2*i/d)
P[k, 2*i] = np.sin(k/denominator)
P[k, 2*i+1] = np.cos(k/denominator)
return P
P = getPositionEncoding(seq_len=128, d=512, n=10000)위치 임베딩을 구해봤으니 실제로 개별 위치에 따라 임베딩 값이 다른지 확인해보겠습니다. 중복 확인을 위해서 엄밀하게는 개별 원소를 하나하나 비교해가며 임베딩 값이 중복되는지 확인해야하지만, 개별 단어의 위치 임베딩 값을 합한 결과를 통해 중복 여부를 확인하여 검증해보도록 하겠습니다.
from collections import Counter
P = getPositionEncoding(seq_len=128, d=512, n=10000)
v = P.sum(axis=1)
Counter(v).most_common()[:5]
# 중복되는 값 없음 => 개별 단어의 위치 임베딩 값은 unique!
[(256.0, 1),
(275.8178576505103, 1),
(276.80232253915267, 1),
(263.1856222076376, 1),
(245.15965393531985, 1)]더 나아가서 임베딩의 원소(i)끼리는 중복이 되는지 확인해보겠습니다. 128개 토큰이 512차원의 임베딩이라 할때 총 128 * 512개의 원소가 존재하게 됩니다. 여기서 개별 원소 값들이 중복되는지 확인해보겠습니다.
from collections import Counter
P = getPositionEncoding(seq_len=128, d=512, n=10000)
v = P.flatten()
Counter(v).most_common()[:5]
# 중복되는 값 존재 => 임베딩의 원소 값은 중복되도 상관없다.
[(0.0, 256),
(1.0, 256),
(0.8414709848078965, 3),
(0.5403023058681398, 3),
(0.5973753250812079, 3)]
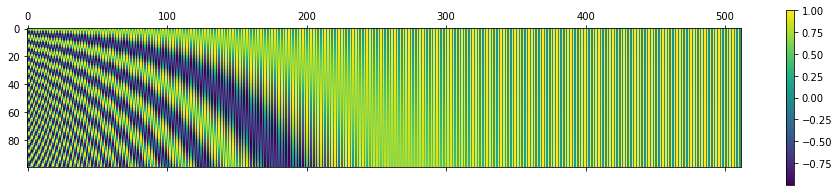
간단한 실험 결과를 종합해보면 단어의 위치 임베딩은 중복이 없지만 내부의 원소들은 중복되도 상관 없음을 알 수 있습니다. 개별 원소가 중복되는 값이 존재함에도 임베딩 차원에서는 중복되지 않는 이유는 아래 그림을 보면 직관적으로 이해하실 수 있습니다. x축은 차원을 나타내며 y축은 단어의 위치를 나타냅니다.
끝으로 Positional Encoding 관련하여 제가 참고했던 자료 + 참고하면 좋을 자료를 소개합니다.