deep learning
Bert From Scratch
Bert 소개
-
Transformer의 encoder 부분만 활용
-
NLP 분야에 Fine-Tuning 개념 도입
-
Masked Language Model[MLM] 뿐만아니라 Next Sentence Prediction[NSP]를 통해 학습
JointEmbedding
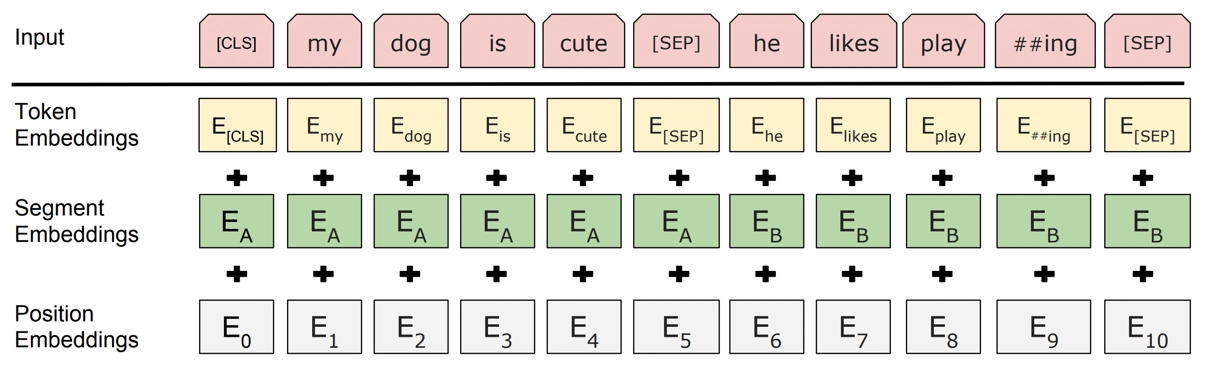
Bert Embedding 종류는 세가지
-
Token Embeddings : token을 indices로 변경
-
Segment Embeddings : 2개 문장의 단어를 구분하기 위해 0,1로 표시 ex) [0,0,0, ... 1,1,1]
-
Position Embeddings : 전체 단어의 순번
import torch
from torch import nn
import torch.nn.functional as f
class JointEmbedding(nn.Module) :
def __init__(self, vocab_size, size, device='cpu') :
super().__init__()
self.size = size
self.device = device
self.token_emb = nn.Embedding(vocab_size, size)
self.segment_emb = nn.Embedding(vocab_size, size)
self.norm = nn.LayerNorm(size)
def forward(self,input_tensor) :
sentence_size = input_tensor.size(-1)
# positional embbeding
pos_tensor = self.attention_position(self.size, input_tensor)
# segment embedding
segment_tensor = torch.zeros_like(input_tensor).to(self.device)
# embedding size의 반은 0 반은 1임
segment_tensor[:, sentence_size // 2 + 1:] = 1
output = self.token_emb(input_tensor) + self.segment_emb(segment_tensor) + pos_tensor
return self.norm(output)
def attention_position(self,dim,input_tensor) :
'''
????
'''
# input_tensor row 크기
batch_size = input_tensor.size(0)
# 문장 길이
sentence_size = input_tensor.size(-1)
# pos 정의 longtype = int64
pos = torch.arange(sentence_size, dtype=torch.long).to(self.device)
# d = sentence 내 허용 token 개수
d = torch.arange(dim, dtype=torch.long).to(self.device)
d = (2*d /dim)
# unsqueeze 공부해야할듯..
pos = pos.unsqueeze(1)
pos = pos / (1e4**d)
pos[:, ::2] = torch.sin(pos[:, ::2])
pos[:, 1::2] = torch.cos(pos[:, 1::2])
# *pos는 처음 보는 방식인데
return pos.expand(batch_size, *pos.size())
#
def numeric_position(self,dim,input_tensor) :
pos_tensor = torch.arange(dim,dtype=torch.long).to(self.device)
return pos_tensor.expand_as(input_tensor)
class AttentionHead(nn.Module):
def __init__(self, dim_inp, dim_out):
super(AttentionHead, self).__init__()
self.dim_inp = dim_inp
self.q = nn.Linear(dim_inp, dim_out)
self.k = nn.Linear(dim_inp, dim_out)
self.v = nn.Linear(dim_inp, dim_out)
def forward(self, input_tensor: torch.Tensor, attention_mask: torch.Tensor = None):
query, key, value = self.q(input_tensor), self.k(input_tensor), self.v(input_tensor)
scale = query.size(1) ** 0.5
scores = torch.bmm(query, key.transpose(1, 2)) / scale
scores = scores.masked_fill_(attention_mask, -1e9)
attn = f.softmax(scores, dim=-1)
context = torch.bmm(attn, value)
return context
class MultiHeadAttention(nn.Module):
def __init__(self, num_heads, dim_inp, dim_out):
super(MultiHeadAttention, self).__init__()
self.heads = nn.ModuleList([
AttentionHead(dim_inp, dim_out) for _ in range(num_heads)
])
self.linear = nn.Linear(dim_out * num_heads, dim_inp)
self.norm = nn.LayerNorm(dim_inp)
def forward(self, input_tensor: torch.Tensor, attention_mask: torch.Tensor):
s = [head(input_tensor, attention_mask) for head in self.heads]
scores = torch.cat(s, dim=-1)
scores = self.linear(scores)
return self.norm(scores)
class Encoder(nn.Module):
def __init__(self, dim_inp, dim_out, attention_heads=4, dropout=0.1):
super(Encoder, self).__init__()
self.attention = MultiHeadAttention(attention_heads, dim_inp, dim_out) # batch_size x sentence size x dim_inp
self.feed_forward = nn.Sequential(
nn.Linear(dim_inp, dim_out),
nn.Dropout(dropout),
nn.GELU(),
nn.Linear(dim_out, dim_inp),
nn.Dropout(dropout)
)
self.norm = nn.LayerNorm(dim_inp)
def forward(self, input_tensor: torch.Tensor, attention_mask: torch.Tensor):
context = self.attention(input_tensor, attention_mask)
res = self.feed_forward(context)
return self.norm(res)Bert 논문 기본 parameter
- Encoder = 12
- heads = 12
- Hidden Layer(=embedding size) = 768
- word piece = 30522(30522개 단어라는 말)
- Parameter = 110M
110M parameter 계산하기
-
30522*768 = 24M(embedding 단어)
-
12 encoder = 84M
- 1 encoder = 7M
- 세부사항은 상세링크 보기
-
Dense Weight Matrix and Bias [768, 768] = 589824, [768] = 768, (589824 + 768 = 590592) = 110M
<a href='https://stackoverflow.com/questions/64485777/how-is-the-number-of-parameters-be-calculated-in-bert-model'>상세 링크</a>
import torch.nn
class Bert(nn.Module) :
def __init__(self,vocab_size,dim_input,dim_output, attention_heads) -> None:
'''
vocab_size : input vocab total
dim_input : (=hidden_layer= embedding_size) 768
dim_output : (=hidden_layer= embedding_size) 768
'''
super().__init__()
self.embedding = JointEmbedding(vocab_size, dim_input)
self.encoder = Encoder(dim_input, dim_output, attention_heads)
self.token_prediction_layer = nn.Linear(dim_input, vocab_size)
self.softmax = nn.LogSoftmax(dim=-1)
self.classification_layer = nn.Linear(dim_input, 2)
def forward(self, input_tensor, attention_mask) :
embedded = self.embedding(input_tensor)
encoded = self.encoder(embedded,attention_mask)
token_predictions = self.token_prediction_layer(encoded)
# 모든 행의 첫번째 단어(embedding)
first_word = encoded[:, 0, :]
return self.softmax(token_predictions), self.classification_layer(first_word)
### First_word 표현 방식 이해용
import torch.nn
import torch
a = torch.arange(0,100).reshape((4,5,5))
a[:,0,:]
tensor([[ 0, 1, 2, 3, 4],
[25, 26, 27, 28, 29],
[50, 51, 52, 53, 54],
[75, 76, 77, 78, 79]])
모델 훈련
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
from datetime import datetime
import time
# dataset_load
import dataset
class BertTrainer :
def __init__(
self,
model,
dataset,
log_dir,
checkpoint_dir,
print_progress =10,
print_accuracy = 50,
batch_size=24,
learning_rate = 0.005,
epochs = 5,
device = 'cpu'
):
self.model = model
self.dataset = dataset
self.device = device
self.batch_size = batch_size
self.epochs = epochs
self.current_epoch = 0
# data 불러오기
self.loader = DataLoader(self.dataset, batch_size=self.batch_size,shuffle=True)
# TensorBoard SummeryWriter 불러오기
self.writer = SummaryWriter(str(log_dir))
self.checkpoint_dir = checkpoint_dir
# NSP 용
# BCEWithLogitsLoss : This loss combines a Sigmoid layer and the BCELoss in one single class.
# BCE = Binary Cross Entropy
self.criterion = nn.BCEWithLogitsLoss().to(self.device)
# MLM 용
# NLLLoss : The negative log likelihood loss. It is useful to train a classification problem with C classes.
self.ml_criterion = nn.NLLLoss(ignore_index=0).to(self.device)
self.optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=0.015)
self._splitter_size = 35
self._ds_len = len(self.dataset)
self._batched_len = self._ds_len // self.batch_size
self._print_every = print_progress
self._accuracy_every = print_accuracy
def __call__(self) :
# Class를 함수처럼 사용하도록 만드는 매서드
for self.current_epoch in range(self.current_epoch,self.epochs) :
loss = self.train(self.current_epoch)
self.save_checkpoint(self.current_epoch)
def train(self, epoch) :
print(f"epoch 시작 {epoch}")
prev = time.time()
# gradient set
average_nsp_loss = 0
average_mlm_loss = 0
# Gradient Descent 시작
for i, value in enumerate(self.loader) :
index = i + 1
# column 별로 불러오기
inp, mask, inverse_token_mask, token_target, nsp_target = value
# Gradient를 Reset 하는 이유
# we typically want to explicitly set the gradients to zero
# before starting to do backpropragation
# (i.e., updating the Weights and biases)
# because PyTorch accumulates the gradients on subsequent backward passes.
self.optimizer.zero_grad()
token,nsp = self.model(inp,mask)
# token mask를 token과 같은 embedding size로 만들기
tm = inverse_token_mask.unsqueeze(-1).expand_as(token)
# False인 경우 0으로 변환
token = token.masked_fill(tm,0)
loss_token = self.ml_criterion(token.transpose(1,2), token_target)
loss_nsp = self.criterion(nsp, nsp_target)
loss = loss_token + loss_nsp
average_mlm_loss += loss_nsp
average_nsp_loss += loss_token
loss.backward()
self.optimizer.step()
if index % self._print_every == 0:
elapsed = time.gmtime(time.time() - prev)
s = self.training_summary(elapsed, index, average_nsp_loss, average_mlm_loss)
if index % self._accuracy_every == 0:
s += self.accuracy_summary(index, token, nsp, token_target, nsp_target,inverse_token_mask)
print(s)
average_nsp_loss = 0
average_mlm_loss = 0
return loss
def save_checkpoint(self, epoch, step, loss):
# Epoch 저장
if not self.checkpoint_dir:
return
prev = time.time()
name = f"bert_epoch{epoch}_step{step}_{datetime.utcnow().timestamp():.0f}.pt"
torch.save({
'epoch': epoch,
'model_state_dict': self.model.state_dict(),
'optimizer_state_dict': self.optimizer.state_dict(),
'loss': loss,
}, self.checkpoint_dir.joinpath(name))
print()
print('=' * self._splitter_size)
print(f"Model saved as '{name}' for {time.time() - prev:.2f}s")
print('=' * self._splitter_size)
print()
def training_summary(self, elapsed, index, average_nsp_loss, average_mlm_loss):
passed = self.percentage(self.batch_size, self._ds_len, index)
global_step = self.current_epoch * len(self.loader) + index
print_nsp_loss = average_nsp_loss / self._print_every
print_mlm_loss = average_mlm_loss / self._print_every
s = f"{time.strftime('%H:%M:%S', elapsed)}"
s += f" | Epoch {self.current_epoch + 1} | {index} / {self._batched_len} ({passed}%) | " \
f"NSP loss {print_nsp_loss:6.2f} | MLM loss {print_mlm_loss:6.2f}"
self.writer.add_scalar("NSP loss", print_nsp_loss, global_step=global_step)
self.writer.add_scalar("MLM loss", print_mlm_loss, global_step=global_step)
return s
def percentage(self,batch_size: int, max_index: int, current_index: int):
"""Calculate epoch progress percentage
Args:
batch_size: batch size
max_index: max index in epoch
current_index: current index
Returns:
Passed percentage of dataset
"""
batched_max = max_index // batch_size
return round(current_index / batched_max * 100, 2)
def accuracy_summary(self, index, token, nsp, token_target, nsp_target, inverse_token_mask):
global_step = self.current_epoch * len(self.loader) + index
nsp_acc = self.nsp_accuracy(nsp, nsp_target)
token_acc = self.token_accuracy(token, token_target, inverse_token_mask)
self.writer.add_scalar("NSP train accuracy", nsp_acc, global_step=global_step)
self.writer.add_scalar("Token train accuracy", token_acc, global_step=global_step)
return f" | NSP accuracy {nsp_acc} | Token accuracy {token_acc}"
def nsp_accuracy(self, result: torch.Tensor, target: torch.Tensor):
"""Calculate NSP accuracy between two tensors
Args:
result: result calculated by model
target: real target
Returns:
NSP accuracy
"""
s = (result.argmax(1) == target.argmax(1)).sum()
return round(float(s / result.size(0)), 2)
def token_accuracy(self, result: torch.Tensor, target: torch.Tensor, inverse_token_mask: torch.Tensor):
"""Calculate MLM accuracy between ONLY masked words
Args:
result: result calculated by model
target: real target
inverse_token_mask: well-known inverse token mask
Returns:
MLM accuracy
"""
r = result.argmax(-1).masked_select(~inverse_token_mask)
t = target.masked_select(~inverse_token_mask)
s = (r == t).sum()
return round(float(s / (result.size(0) * result.size(1))), 2)
Torch.argmax(1)의미
- argmax 중 2차원을 기준으로 가장 큰 값 찾기
import torch
a = torch.randint(0,100,(3,4))
print(a)
print(a.argmax(1))
tensor([[22, 32, 77, 25],
[76, 66, 85, 40],
[62, 92, 95, 7]])
tensor([2, 2, 2])
a = dataset.IMDBBertData("./data/IMDB Dataset.csv", should_include_text=True)
a.vocab(["here", "is", "the", "example"])
vocab 생성
100%|██████████| 491161/491161 [00:05<00:00, 94854.76it/s]
데이터 전처리 시작
100%|██████████| 50000/50000 [00:39<00:00, 1270.98it/s]
[646, 30, 7, 2484]
EMB_SIZE = 64
HIDDEN_SIZE = 36
EPOCHS = 4
BATCH_SIZE = 12
NUM_HEADS = 4
BERT = Bert(len(a.vocab), EMB_SIZE, HIDDEN_SIZE, attention_heads= NUM_HEADS).to('cpu')
trainer = BertTrainer(BERT,a,'./data/','./data/', batch_size=BATCH_SIZE,
learning_rate=0.00007,
epochs=EPOCHS)
trainer()
epoch 시작 0
00:00:04 | Epoch 1 | 10 / 73526 (0.01%) | NSP loss 1.14 | MLM loss 0.08
00:00:09 | Epoch 1 | 20 / 73526 (0.03%) | NSP loss 1.12 | MLM loss 0.07
00:00:13 | Epoch 1 | 30 / 73526 (0.04%) | NSP loss 1.12 | MLM loss 0.07
00:00:18 | Epoch 1 | 40 / 73526 (0.05%) | NSP loss 1.12 | MLM loss 0.07
00:00:22 | Epoch 1 | 50 / 73526 (0.07%) | NSP loss 1.12 | MLM loss 0.08 | NSP accuracy 0.17 | Token accuracy 0.0
00:00:27 | Epoch 1 | 60 / 73526 (0.08%) | NSP loss 1.12 | MLM loss 0.07
00:00:31 | Epoch 1 | 70 / 73526 (0.1%) | NSP loss 1.12 | MLM loss 0.08