[Kubeflow] Kserve로 pytorch 모델 서빙하기
들어가며
이 글은 kserve를 활용해 pytorch model을 서빙하는 방법을 설명합니다. 이전 글인 🤗 Transformers를 활용해 Torchserve 배포하기에 기반해 작성한 글이므로 링크에 연결된 글을 읽고 이 글을 읽는 것을 권장합니다.
Kserve 구조
아래 그림은 Kserve에 모델을 배포하고 이를 활용하는 구조를 나타냅니다. Kserve의 구조는 Deployment과 Infernece로 구분지을 수 있습니다.
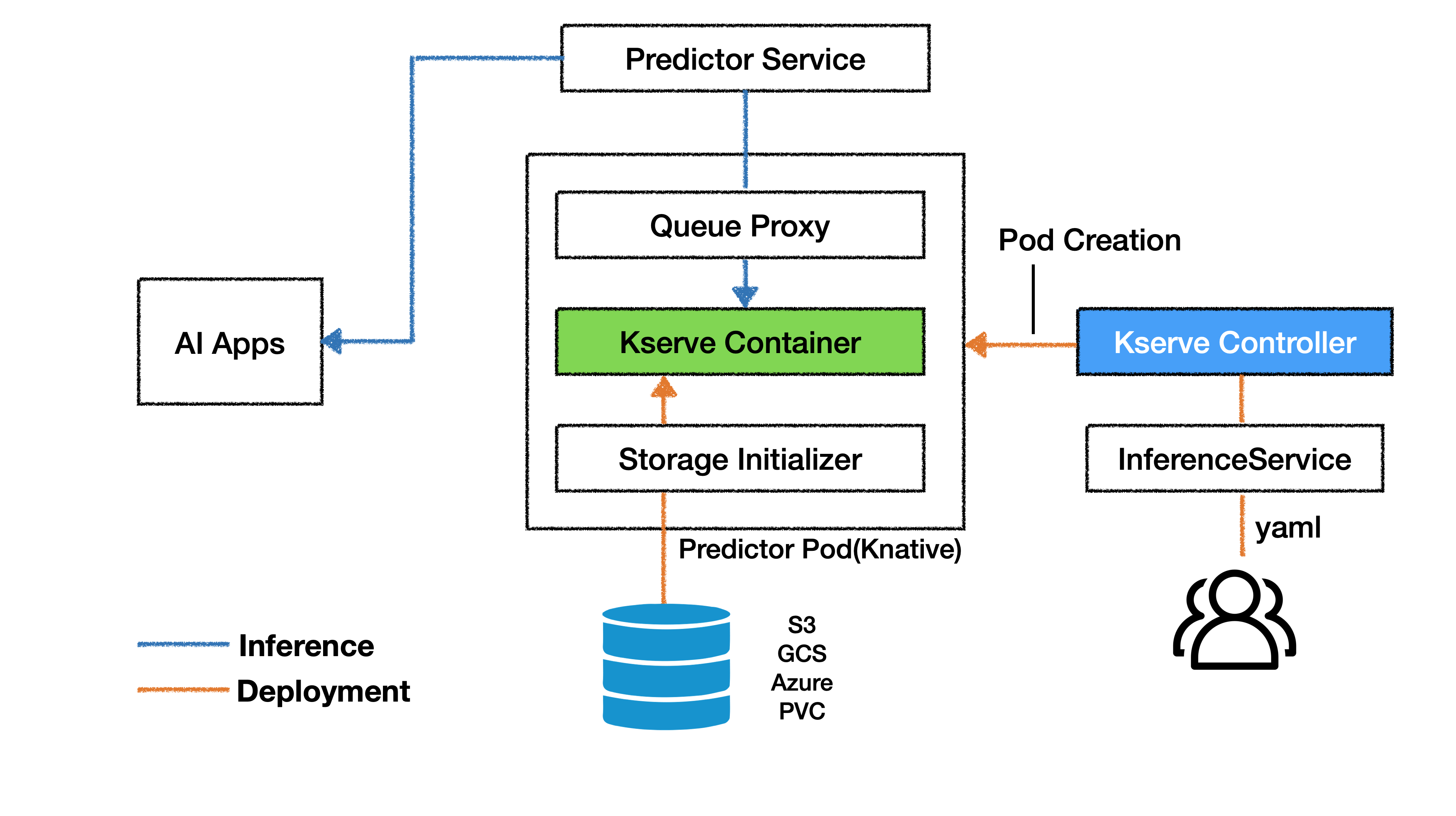
❖ Deployment
Deployment 과정을 의미하는 주황색 실선은 모델이 배포되는 과정을 나타냅니다. 사용자는 커스텀 리소스인 InferenceService에게 설정을 담은 yaml 파일을 제출하여 Inference 모델을 생성을 요청합니다. yaml의 설정 값은 Kserve Controller로 전달되며, Kserve Controller는 설정값을 바탕으로 Pod를 생성합니다. 이때 생성되는 Pod를 Predictor Pod라 합니다.
Predictor Pod가 생성되면 Pod 내부에서는 Storage Initializer를 실행합니다. Storage Initializer는 Serving 모델 구동에 필요한 파일을 Storage로부터 불러오는 단계이며 정해진 경로에 있는 파일과 폴더를 Kserve Container에 저장합니다. 파일을 불러오는 경로로 S3, GCS 같은 외부 storage를 활용할 수도 있고 내부 PVC를 활용할 수도 있습니다.
Pytorch 모델을 배포할 경우 Storage Initializer는 Storage 내부에 정해진 경로에 위치한 Mar file과 config.properties를 Kserve Container로 복사합니다. Storage initializer가 파일을 불러오는 경로는 매번 동일하므로 정해진 경로에 맞춰 Mar file과 config.properties 파일을 미리 위치시켜 놓아야합니다. 세부적인 경로 설정 방법은 pytorch 모델 서빙하기 문단에서 설명하도록 하겠습니다.
Torchserve 구동에 필요한 파일인 Mar file과 config.properties가 Kserve Container로 옮겨지면 Kserve container는 config.properties에 설정값을 바탕으로 Torchserve를 구동합니다. 서버가 문제없이 실행됐다면 별도의 서버 설정 없이 API를 통해 외부에서 모델을 사용할 수 있습니다.
❖ Inference
사용자는 Kserve를 활용해 모델을 배포함으로서 외부 통신을 위한 서버 구축 과정을 생략하게 됩니다. Kserve의 기반인 Knative가 API 통신에 필요한 기능을 자동으로 구축하기 때문입니다. 모델에 대한 요청과 응답은 위 그림의 파란색 실선의 과정을 거쳐 수행됩니다.
AI Apps는 Kserve가 요구하는 정해진 양식에 맞춰 데이터를 담아 요청을 보냅니다. AI apps의 요청은 Ingress-gateway와 Predictor Service를 거쳐 Predictor Pod로 전달됩니다. Predictor service는 외부 요청이 현재 가동중인 Inference 모델 중 어떠한 모델을 대상으로 요청하는지를 확인하고 데이터를 전달해주는 역할을 수행합니다.
Predictor Pod 내부의 데이터 전달 과정을 보겠습니다. 위 그림에는 표현되지 않았으나 Predictor service의 전달 값은 Pod 내부에서 Istio-proxy가 이어받게 되며 이를 다시 Queue Proxy에 전달합니다. Queue Proxy는 다시 Kserve Container에 전달합니다. Kserve Container 내부에서는 요청 받은 데이터 중 Inference 모델에 필요한 데이터를 추출하고 Torchserve가 설정한 IP 주소와 포트에 맞춰 데이터에 전달합니다.
Knative에서 데이터가 전달되는 전반적인 과정은 아래의 그림과 같습니다. 그림에서 Kserve에 해당되는 구조는 주황색의 User Container 입니다.
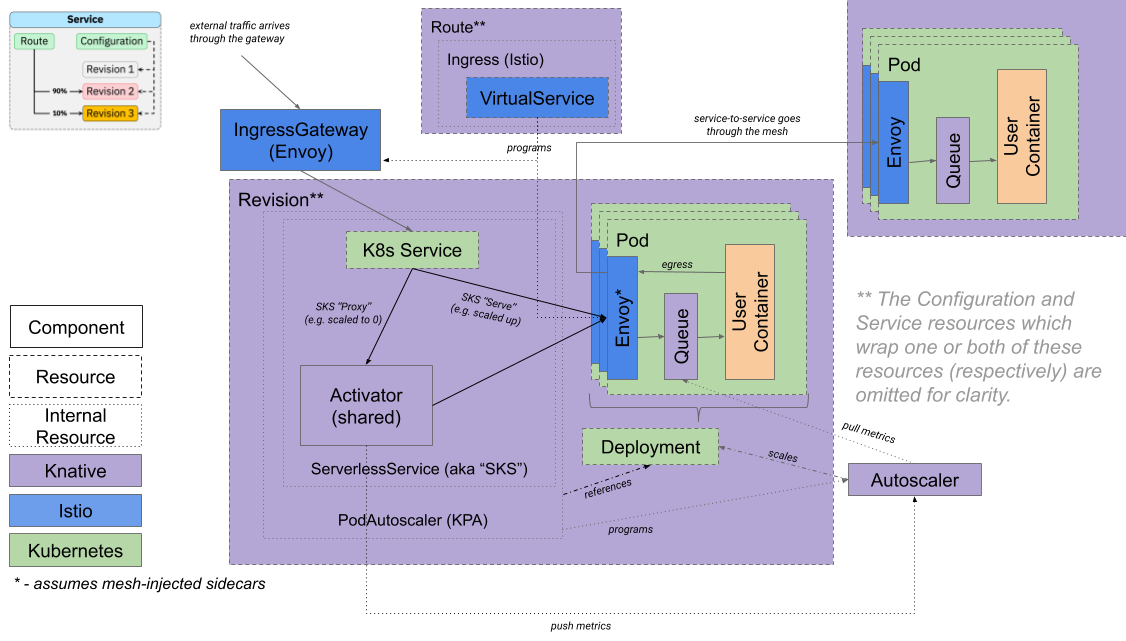
Kserve에 PyTorch 모델 서빙하기
이제 Kserve를 활용해 pytorch 모델을 서빙해보겠습니다.
❖ PVC 생성 및 Mar file, config.properties 저장
yaml 파일을 작성해 쿠버네티스에 제출하기 전 Mar file과 config.properties를 Storage에 저장해야 합니다. Predictor Pod가 실행되면 Storage Initializer를 통해 Torchserve 구동에 필요한 Mar file과 config를 kserve Container에 복사해야하기 때문입니다.
이번 예제는 Storage로 PVC를 활용하겠습니다, PVC는 Volume 항목에서 쉽게 생성할 수 있으며 Notebook을 활용한다면 PVC 내부에 쉽게 접근할 수 있습니다. kubeflow dashboard의 volume 항목을 선택해 PVC를 생성하겠습니다.
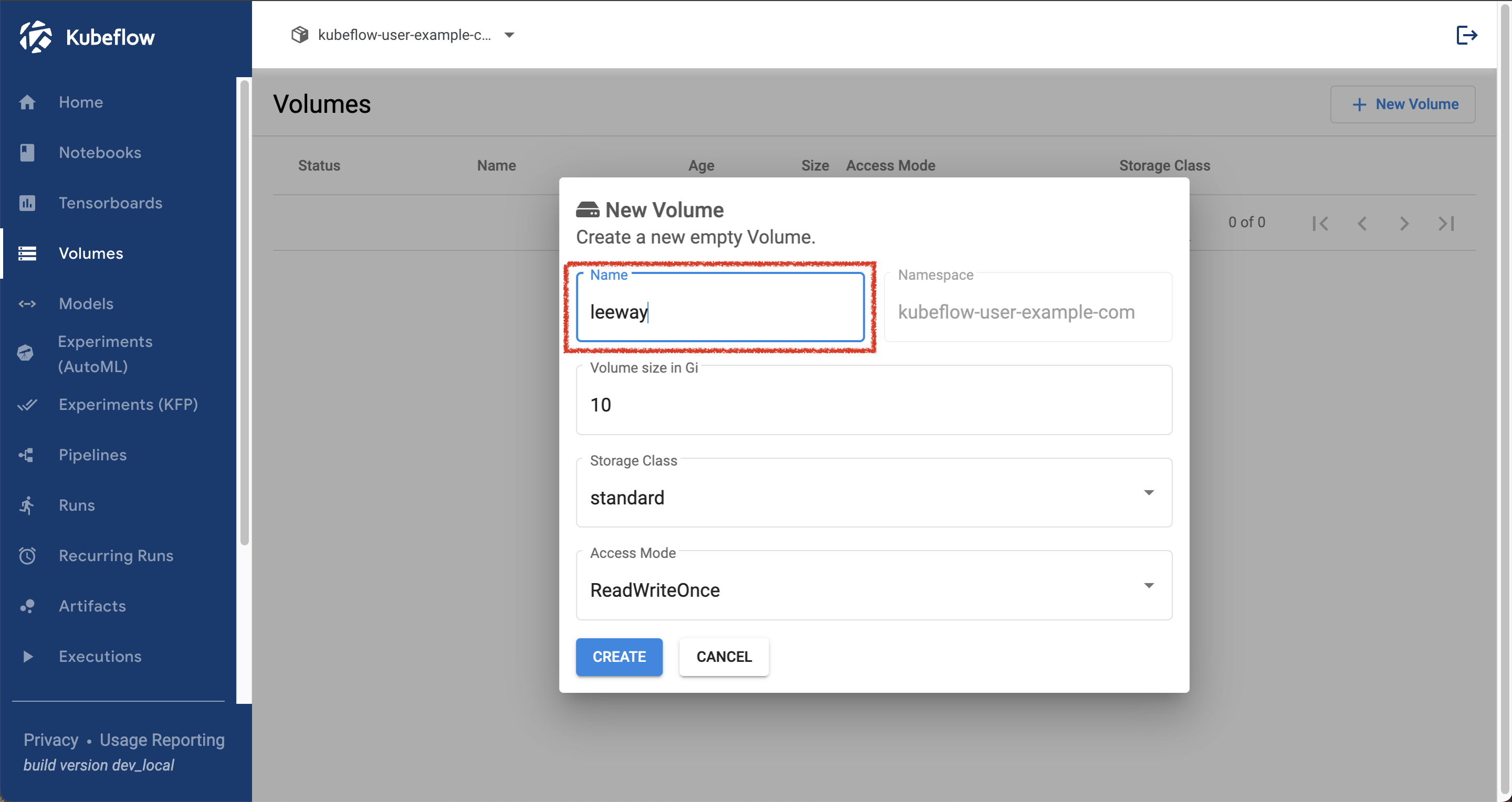
다음으로 notebook 항목으로 넘어가 노트북을 새로 만들겠습니다. 노트북 생성시 Workspace volume에 자동으로 마운트 된 volume을 제거하고 아래 Data Volume에서 방금 생성한 pvc를 추가합시다.
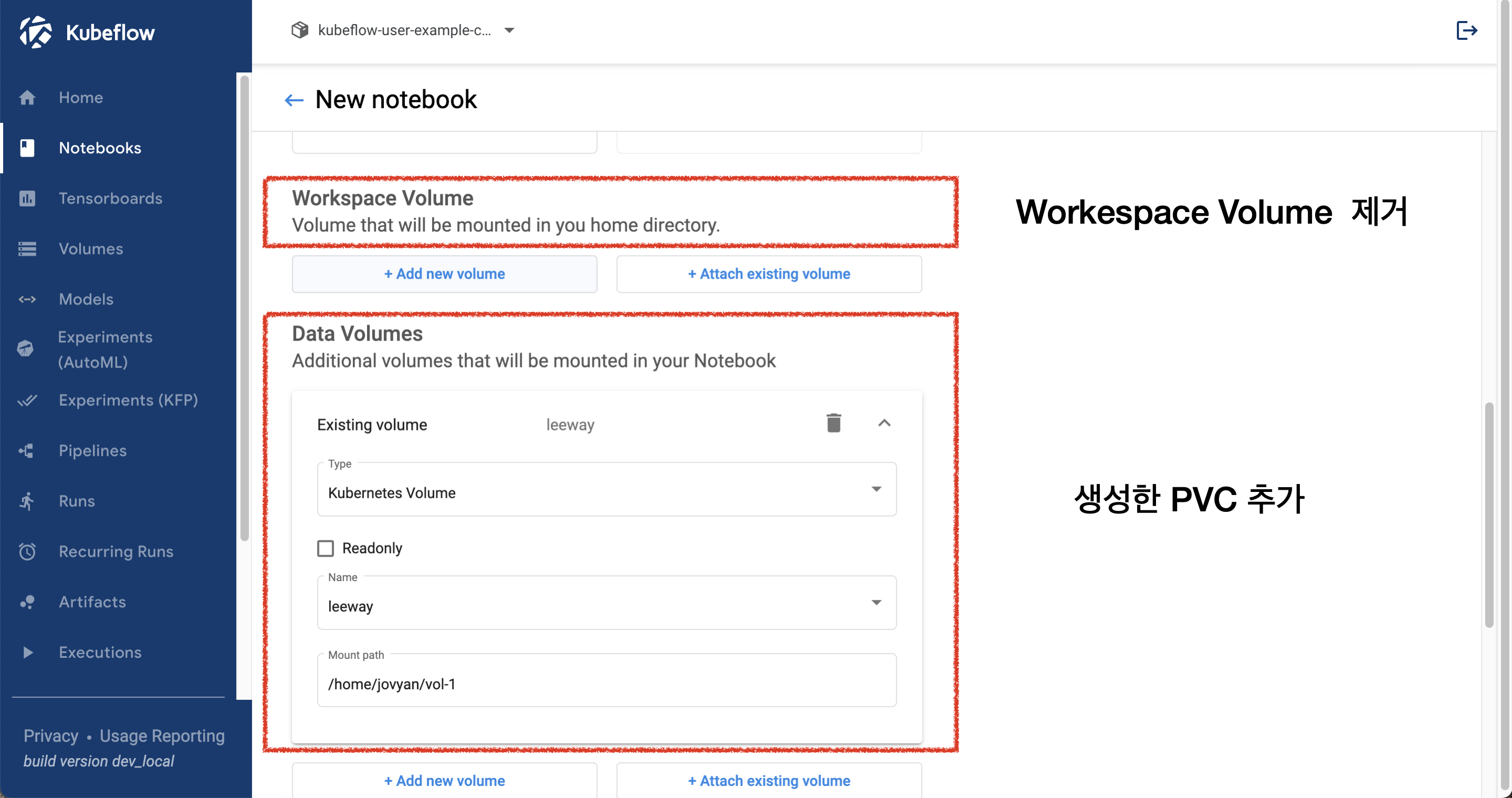
생성된 notebook으로 들어가 vol-1 폴더에 접근합니다. vol-1 폴더 내부는 leeway pvc의 시작 디렉토리(/)와 동일한 경로입니다. vol-1 내부에 파일을 생성하면 leeway pvc에 저장되며, 저장된 데이터는 leeway pvc를 사용하는 모든 컴포넌트에서 활용 할 수 있습니다.
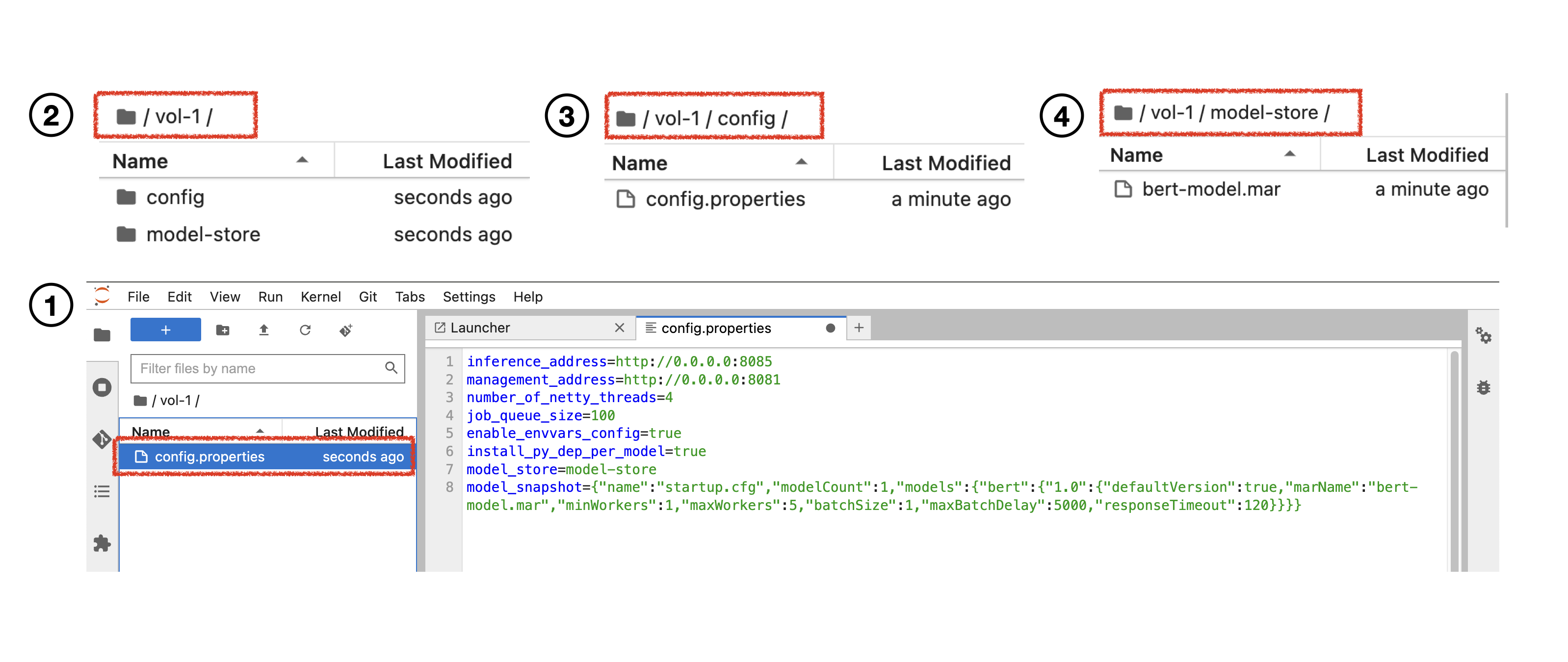
이제 torchserve 구동에 필요한 파일을 leeway pvc에 저장하겠습니다. 먼저 config.properties 파일을 만들기 위해 notebook vol-1 폴더 내부에 text file을 생성하고 아래의 내용을 붙여넣습니다. 파일명을 config.properties로 변경하고 config 폴더를 생성하고 파일을 폴더 내부로 옮깁니다. ---- 그림 1, 2, 3번
config Parameter에 대한 세부 설명은 Pytorch Docs를 참고하세요.
inference_address=http://0.0.0.0:8085
management_address=http://0.0.0.0:8081
number_of_netty_threads=4
job_queue_size=100
enable_envvars_config=true
install_py_dep_per_model=true
model_store=model-store
model_snapshot={"name":"startup.cfg","modelCount":1,"models":{"bert":{"1.0":{"defaultVersion":true,"marName":"bert-model.mar","minWorkers":1,"maxWorkers":5,"batchSize":1,"maxBatchDelay":5000,"responseTimeout":120}}}}🤗 Transformers를 활용해 Torchserve 배포하기에서 생성했던 Mar file을 model-store 폴더에 업로드 합니다. ---- 그림 4번
❖ yaml 파일 생성
이제 Inference 모델을 생성하기 위한 yaml 파일을 생성하겠습니다. 아래의 양식 중 name과 storage uri를 개인 설정 값으로 변경해야 합니다. storage uri 작성시 주의할 점은 notebook에서 pvc 접근 시 사용했던 vol-1 폴더를 경로에 포함하지 않는 것입니다. notebook에 있는 vol-1은 notebook에서 leeway pvc를 접근으로 위한 관문 용도이며 pvc 내부에 존재하는 경로가 아닙니다. 따라서 노트북에서 생성한 mar-store 폴더와 config 폴더의 경로는 leeway/vol-1/mar-store가 아닌 leeway/mar-store, leeway/config가 됩니다.
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "torchserve" # 배포 모델명
spec:
predictor:
model:
modelFormat:
name: pytorch
storageUri: "pvc://leeway" # mar-store, config 폴더가 있는 경로
protocolVersion: v1
resources:
limits:
cpu: 2
memory: 2Gi
requests:
cpu: 0.5
memory: 0.5Gi❖ yaml 파일 제출
kubeflow model 항목으로 이동하여 앞서 작성한 yaml 파일을 실행합시다. 모델 페이지에서 제공하는 실행 표시는 Predict Pod 내부 진행 상태를 반영하지 않으므로 Predictor Pod 내부에 있는 컨테이너를 직접 체크해 에러 여부를 확인해야 합니다. Predictor Pod가 정상적으로 실행 됐는지 추적하기 위해 쿠버네티스의 내부 현황을 모니터링하는 도구인 k9s를 사용하겠습니다. 맥 사용자는 brew install k9s로 쉽게 설치할 수 있습니다.
k9s를 실행한 뒤 Shift + A 를 눌러 최신 실행된 순으로 pod를 나열합니다. Predictor Pod에 커서를 위치한 뒤 enter를 눌러 내부 컨테이너로 넘어갑니다. 컨테이너 내부는 아래와 같이 istio-proxy, queue-proxy, kserve-container(Kserve Container), storage-initializer가 포함되어 있음을 확인할 수 있습니다.
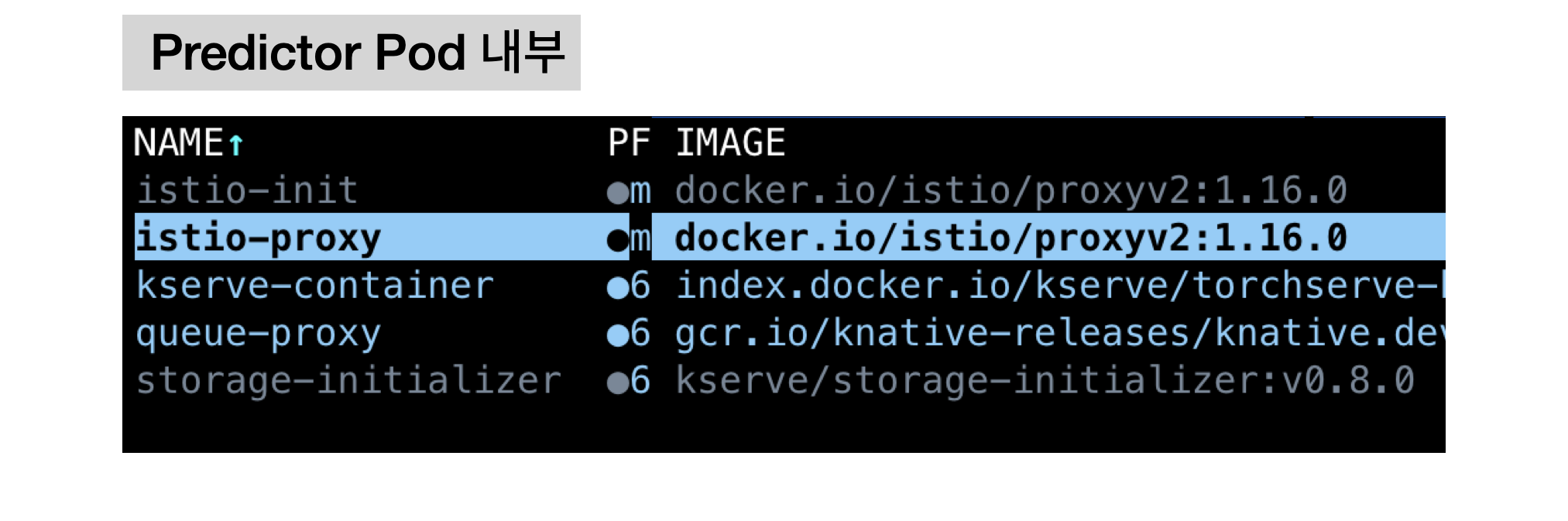
이중 가장 아래에 있는 storage-initializer에 위치를 두고 l 버튼을 눌러 컨테이너 로그를 확인합니다. storage-initializer 로그를 보면 정상적으로 mar-store 폴더와 config 폴더가 kserve container와 연동되었음을 확인 할 수 있습니다.

다음으로 kserve-container의 로그를 확인해 Torchserve가 에러 없이 정상 실행했는지를 확인하겠습니다. 로그를 보니 별다른 에러 없이 정상 실행되고 있음을 확인할 수 있습니다.
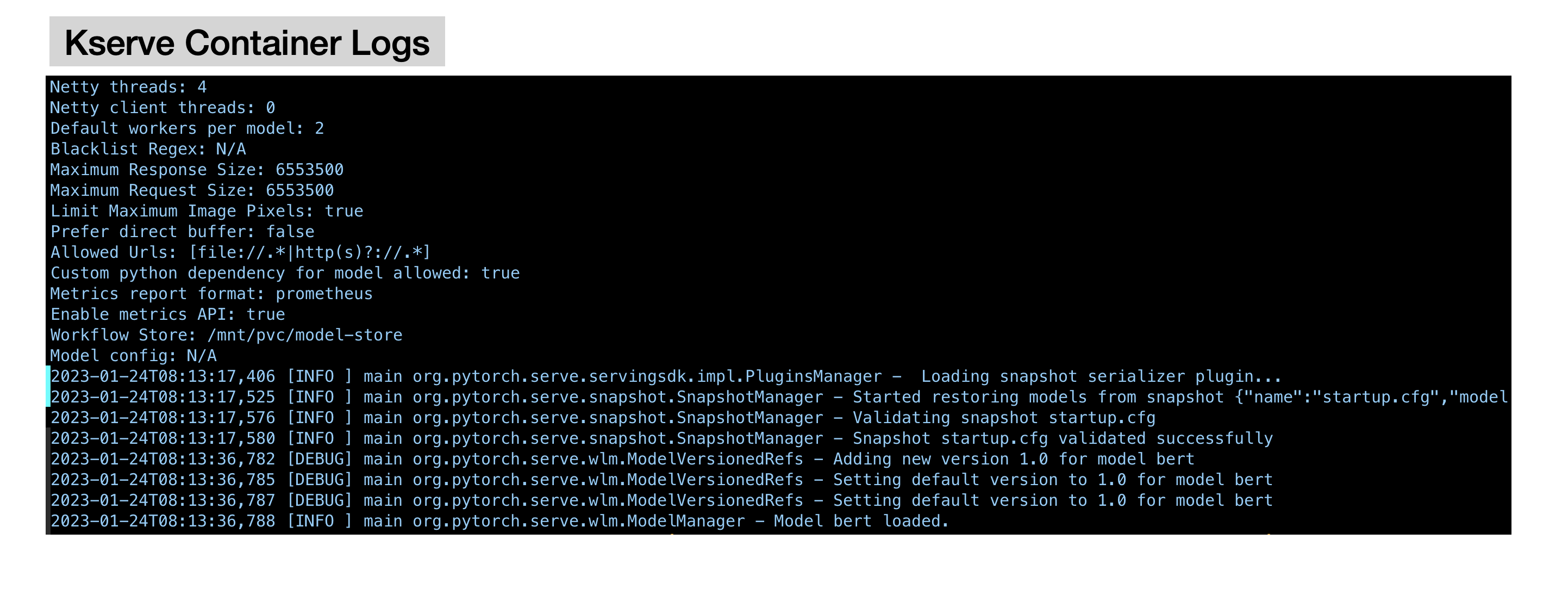
❖ 요청에 필요한 변수 설정
Inference 모델을 정상적으로 배포한 것 같으니 이제 외부에서 모델로 요청을 보내보겠습니다. 먼저 서버 요청시 준수해야할 데이터 형식과 요청에 필요한 필요한 Model Name, Session, Host name설정 방법을 설명하겠습니다.
Inference Service에 요청을 보내기 위해선 정해진 데이터 형식을 준수해야합니다. Kserve-container는 양식에 맞는 데이터에서 Torchserve로 건내줘야하는 데이터를 자체적으로 추출하기 때문입니다. 따라서 Torchserve에 실제 요청하는 데이터는 아래의 양식에 있는 data 부분에 담아서 보내야 합니다.
아래의 json을 복사해 로컬 폴더에 sample.json으로 저장합니다. sample.json은 외부 데이터 전송 테스트용으로 활용할 예정입니다.
{
"instances": [{ "data": "Hello World!" }]
}MODEL_NAME은 Torhserve 설정값인 config.properties의 모델명을 의미합니다. yaml에 작성한 이름(torchserve)이 아니므로 주의해야 합니다. config.properties를 수정하지 않고 붙여넣었다면 기본 모델 Name은 bert 입니다.
# config.properties
model_snapshot={"name":"startup.cfg","modelCount":1,"models":{"bert" <= MODEL_NAME {"1.0":{"defaultVersion":true,"marName":"bert-model.mar","minWorkers":1,"maxWorkers":5,"batchSize":1,"maxBatchDelay":5000,"responseTimeout":120}}}}Session은 서버에서 클라언트를 인증하기 위한 용도로 활용하는 쿠키입니다. kubeflow로그인 후 브라우저 개발자도구 ⇒ 애플리케이션 ⇒ 쿠키 ⇒ authservice_session에서 확보 합니다.
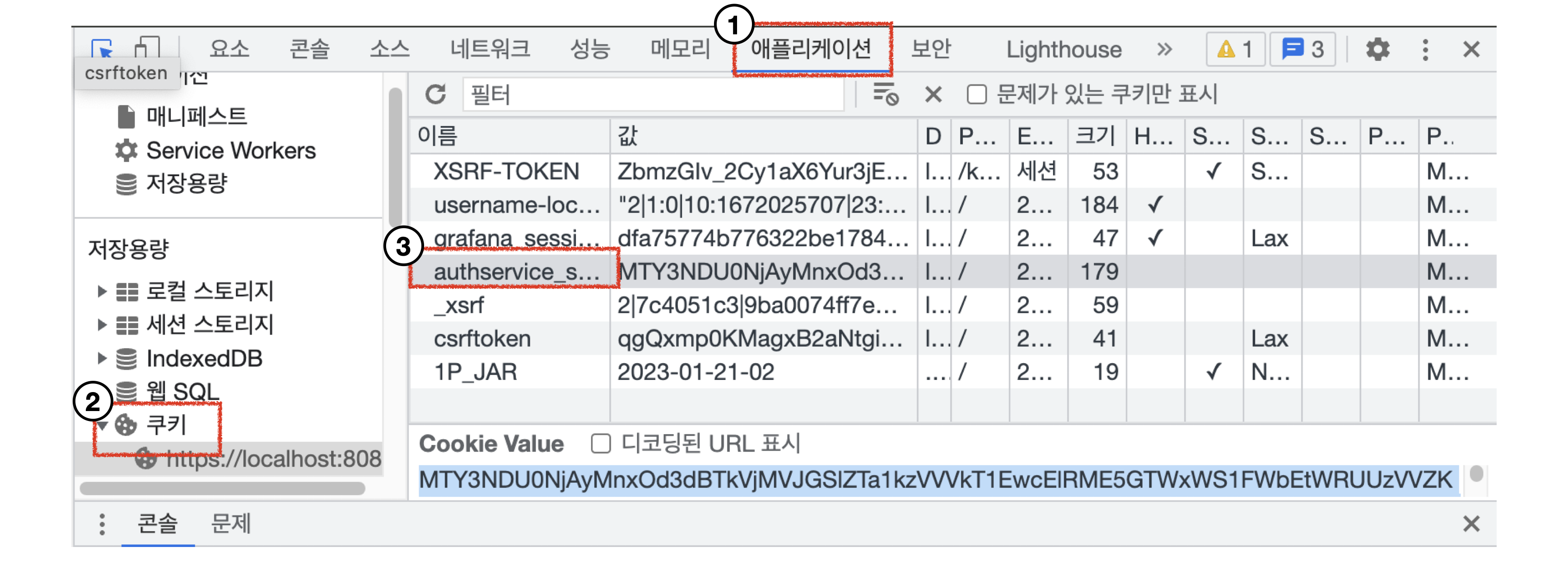
SERVICE_HOSTNAME은 {모델명}.{namespace}.example.com으로 구성됩니다. 모델명은 업로드한 yaml 이름(torchserve)입니다.
MODEL_NAME, SESSION, SERVICE_HOSTNAME을 변수로 저장합니다.
# model 업로드에 사용한 모델명 X, config.properties에서 설정한 모델명 O
export MODEL_NAME=bert
# Auth Session key 브라우저 개발자도구 => 애플리케이션 => 쿠키 => authservice_session
export SESSION=MTY3NDU0NjAyMnxOd3dBTkVjMVJGSlZTa1kzVVVkT1EwcElRME5GTWxWS1FWbEtWRUUzVVZKTVVFWktXREpZVUZGTk5rMUNWbG8wUnpaV1NrVlZUMUU9fKlskygrmWOb_KaYh0CfGGToaDzJHVf_fojh2ppH4-FT
# {yaml에 작성한 모델명}.{namespace}.example.com
export SERVICE_HOSTNAME=torchserve.kubeflow-user-example-com.example.com❖ Inference 모델에 요청하기
변수 설정을 완료했다면 Inference 모델에 요청하도록 하겠습니다. 요청의 결과로 {"predictions": [4]}와 같은 양식을 반환하면 성공입니다.
### HTTP 사용 시
curl -v -X POST -H "Host: ${SERVICE_HOSTNAME}" -H "Cookie: authservice_session=${SESSION}" http://localhost:8080/v1/models/${MODEL_NAME}:predict -T sample.json
### HTTPS 사용 시
curl -k -v -X POST -H "Host: ${SERVICE_HOSTNAME}" -H "Cookie: authservice_session=${SESSION}" https://localhost:8080/v1/models/${MODEL_NAME}:predict -T sample.json
# request 결과
>>> {"predictions": [4]}